GusOnGames
Physics Simulation & Game Development
The C++ Programming Language
Part 4: Pointers & References
Pointers are a very powerful tool we have in C++. They allow us to access the memory directly to read or alter its contents.
Pointers
A pointer is a new type of variable. It is used to store the address aka the position in computer memory of another variable. This allows you to reference and manipulate the data stored at that address.
Here are some common uses of pointers:
Dynamic Memory Allocation: Allocate memory during runtime using new and delete.
Function Arguments: Pass large structures or arrays efficiently.
Data Structures: Implement complex data structures like linked lists, trees, and graphs.
Besides the obvious advantages we have from the common uses, pointers is a very powerful characteristic of C++ for two more reasons
Efficiency: using pointers we can have direct access to the memory which can make our programs faster.
Flexibility: it is easier to use and manipulate complex data structures required by big programs.
But as usually there is a price we got to pay for all this:
Dangling Pointers: Pointers that reference deallocated memory.
Memory Leaks: Forgetting to free dynamically allocated memory.
Dangerous if not mastered: Can lead to errors if not handled carefully.
Pointer syntax
To declare a pointer, we use the asterisk (*) symbol, also known as the dereference operator:
int* intPtr; // a pointer to an integerA pointer needs to point to a variable. For this we use the address off operator (&).
From now on we have two ways to access the contents of int_var. One via the variable name like we have done so far and one via the pointer:
int* intPtr; // a pointer to an integer
int int_var; // an integer variable
intPtr = &int_var; // the pointer now points to the variable
Note that the variable intPtr is an address in the computer memory so to access its contents, aka the value of int_var, either to modify or to read, we have to use the dereference operator (*).
int_var = 10; // setting the value
std::cout << int_var << "\n";
*intPtr = 12; // and changing it
std::cout << int_var << ", " << *intPtr << "\n";
Dynamic Memory Allocation
In our programs we need to handle varying amounts of data. This raises the need for dynamic memory management. We need the flexibility to reserve different sizes of memory based on our needs. The operating system has these mechanisms and in C++ we can access them with pointers.
A pointer can point to a chunk of memory the system has reserved for us. Then se can use it to store and retrieve data for our needs.
The new operator
We use the new operator to request memory from the system:
data_type* var = new data_type;This allocates one item of type data_type. We can allocate as many as we need to. In the example we allocate an arbitrary number of integers:
int many = 100;
int* dynPtr = new int[many];
We use a variable in the allocation to show that the call to the new operator is dynamic. If the allocation succeeds, we end up with space enough to store 100 integers. Say we want to hold the scores of 100 players in a game.
Accessing the dynamically allocated memory
To access the allocated memory, we have two different ways. One is using pointer arithmetic and one is using array notation.
Pointer Arithmetic since a pointer is actually a variable containing a memory address if we modify its value it points to a different location. Note the difference between the pointer and the address it points to. Look at this code:
++dynPtrThis increases the pointer by one (1) making it point to the next position in memory. It does not increase the value of the contents in the location it points to. To access the contents, we have to use the dereference operator (*).
The nice thing about pointer arithmetic is that the increment operator advances the pointer to the next element based on the allocation type, in our example integer. Similarly, the decrement operator goes back one element. We can even add an integer, and the pointer will advance as many places as the value of the integer.
In this example we go over all the allocated memory and set some value:
int many = 100;
int* dynPtr = new int[many];
int* hiScores = dynPtr; // another pointer to the same location
// iterating over the allocated memory with pointer arithmetic
for (int i = 0; i < many; ++i) {
*hiScores = i; // set the value
++hiScores; // advance the second pointer
// adding an index to the first pointer
std::cout << *(dynPtr + i) << "\n";
}
We created a second pointer and made it point to the same location as the first pointer. There is no limit in the number of pointers we can have pointing to the same location. We use both the pointer increment and the indexing to access the memory. Here we show the difference between modifying the pointer and modifying the contents of the memory it points to.
The big mistake programmers make when dealing with pointers is accessing memory beyond the limits of the memory allocated. If you change the loop limit from many to many+10 and run the program, it will crash when the pointer goes path the last allocated entity.
The delete operator
When we no longer need the memory we must return it to the operating system. If we keep requesting for memory we do not return to the system we end up with what is called memory leak. This may lead even to system crash.
The delete operator is used to free the allocated memory and return it to the system:
delete [] dynPtr;The square brackets tell the delete operator that we are not deallocating a single entity but an array of entities.
Here is how we treat one entity:
int* somePtr = new int;
delete somePtr;
The pointer we used to point to an integer variable cannot be deleted. Calling delete on it will lead to a compilation error.
A common mistake with pointers is continue using them after they have been deleted. In the example above we had two pointers referencing the same memory: dynPtr and hiScores. After deleting dynPtr we can still use them both. Playing around with the pointer itself is safe, after all it is just a variable, the problems start when we try to access the memory it points to.
The code in this example leads to a crash:
delete [] dynPtr;
hiScores = dynPtr;
for (int i = 0; i < 10; ++i) {
*(hiScores + i) = 1000;
}
This code has the second of the two big mistakes which are common when dealing with pointers. It is attempting to directly modify the contents of the memory after it has been deleted. The first being the out of bounds memory access.
Create an array in C++
In C++ we can create an array that can be as big as we need, using the standard library. These arrays have a built-in mechanism that performs the allocation of the required memory and to release that memory when no longer needed. We still have the benefits of dynamic memory allocation without the low-level management. They rely on the characteristics of the language we will examine later.
Such a dynamic array is the std::vector. It is declared in the header <vector> and can contain any kind of data we like. We specify the data it will hold upon declaration of a vector type variable:
std::vector vec{ 1,2,3,4,5,6,7,8,9,10 }; Here we create a vector of integers and initialize it with some data. When the variable goes out of scope the memory is released and we do not have to worry about any memory leaks.
Function arguments
Pointers give us a lot of flexibility when used as functions arguments.
Pointers as references to variables
Pointers are used in function arguments when we want to pass the value of a variable but a reference to it. This means that the called function knows the location of our variable and can read or modify it instead of getting just a copy of it. Passing a reference of our variable is essential when we need the called function to modify its value.
Here is an example of this:
int byrefInt(int* val) {
*val = 2 * (*val);
return 1;
}
Our function takes an integer and doubles it. And this is how we call it:
int cv = 12;
byrefInt(&cv);
std::cout << cv << "\n";
The function has a local variable (val) which is a pointer to an integer. This value is initialized with the address of the cv variable of the calling function. So, when we go *val = 2 * (*val); we read and modify the cv variable via it pointer val.
Efficient passing of large objects
Passing large objects like the array we allocated earlier by creating a copy, or by value as is the technical term, is very slow. Instead of copying our data to a new variable it is a lot more efficient to pass a pointer to our data, we actually copy an address and we are done.
We create a function that summarizes the numbers in an array:
int sum_data(int* data, int many) {
int sum = 0;
for (int i = 0 i < many; ++i) {
sum += *data;
++data; // point to the next in line
}
return sum;
}
This function is very flexible. It gets the array and the number of elements we want to include in our calculation. The many variable cannot exceed the number of elements we allocated and we have to pass it because the function does not know when to stop.
In the function we modify the pointer to move it to the next item. The pointer belongs to the function, only the data belong to the caller. It is a local function and a copy of the caller’s pointer.
Here is how we call the function:
int s = sum_data(dynPtr, many);
std::cout << "s=" << s << "\n";
References
In C++, references are essentially aliases for existing variables. They allow you to create another name for a variable, which can be used to access or modify the original variable. References were first created to substitute the pointers when used as references to variables as we saw earlier.
References have several advantages over them by design.
Simplified Syntax: References do not require explicit dereferencing, making the code cleaner and easier to read. You can use them just like normal variables.
Memory Efficiency: References do not consume extra memory as they share the same memory address as the variable they refer to. This is unlike pointers, which need additional space for storing the address.
Safety: Since references must be initialized when they are declared, they are less prone to errors like null or wild pointers.
Performance: Passing large objects by reference avoids the overhead of copying the object, which can save both time and memory.
Function Parameters: References allow functions to modify the given parameters directly, which can be useful for functions that need to alter the input variables.
Consistency: Once a reference is initialized to a variable, it cannot be changed to refer to another variable, ensuring consistent behavior.
Creating a Reference
To create a reference, we use the ampersand (&) symbol:
int var;
int& ref = var;
The reference ref is initialized to the variable var right at the declaration. From that point on any changes made to ref will be reflected to var and vice versa:
ref = 14;
std::cout << "var=" << var << "\n";
Function parameters
We can use references as function parameters instead of pointers when we need to pass a variable by reference or pass large objects like arrays.
int byrefVar(int& ref) {
ref = 24;
return 1;
}
We call the function like this:
int var;
byrefVar(var);
std::cout << "var=" << var << "\n";
We pass the variable, and the compiler automatically generates the reference the called function expects.
Avoid copying of large objects
We can use references to avoid copying large objects like std::vectors of objects. We were introduced to vectors earlier. A function that takes vector of integers is like this:
void modifyVector(std::vector<int>& v) {
for (int i = 0; i < v.size(); ++i)
v[i] += 3;
}
The vector is aware of the allocated size, and we no longer need it as argument in the function.
We create and pass to a function like this:
std::vector<int> vec{ 1,2,3,4,5,6,7,8,9,10 };
modifyVector(vec);
// view the results
for (int i = 0; i < vec.size(); ++i)
std::cout << vec[i] << "\n";
Key points when using references
Initialization: References must be initialized when declared.
Immutability: Once a reference is bound to a variable, it cannot be changed to refer to another variable.
Computer memory organization
C++ allows us to allocate memory dynamically at runtime. Here we are going to see how C++ organizes computer memory and where everything resides. These are essential for a C++ developer and can make a huge difference in the quality of our programs.
Basic memory organization of a C++ program
Computer programs are given memory space upon start up. The amount of this memory is really big, theoretically close to the total system memory. This is not physical and reserved for the program though. It is a virtual space managed by the operating system, but our code cannot tell the difference. It communicates with the operating system with compiler vendor supplied libraries and handles all its requirements.
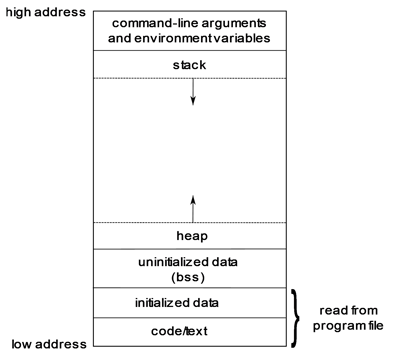
To access this memory we use addresses, aka numbers referring to the location of the data in memory. These addresses start from 0 and go as high as the system supports. Address near the bottom, or 0, is called low address and at the top is called high address.
In this memory we have everything our program needs.
- At the lowest memory address, we have the code/text area. There the operating system loads the machine code instructions the processor executes when running our program. This memory is read-only. It is protected by the processor and when any other program tries to modify it the system crashes. This memory can be shared between multiple instances of the program.
- Initialized data segment. This segment contains the initialized global and constant variables. These are the variables that were declared and initialized in our code. Variables that can be modified are placed in the read-write area while variables declared as const are placed in the read-only area.
- Uninitialized data segment. Here are stored all the global variables that were not initialized in the code. Some compilers initialize all the variables in this segment to 0, but there is no guarantee that this will always be the case.
- Heap. This area is monitored and controlled by the system. Here is where we gain access via the dynamic memory allocation mechanism we saw earlier. Although in modern systems this is a very big area responsible bookkeeping from our program is always required. We must always release any memory we no longer need so that other parts of our program will run smoothly when requesting memory.
- Stack. This area is used for the local variables and the arguments of the functions in our program. Every time a function is called, a new stack ‘frame’ is allocated to store the locals and the arguments. This ensures that each invocation has its own copy of the variables allowing for recursive function calls (functions can call themselves). This stack ‘frame’ is released when the function exits, signaling the end of life for local variables. This is the reason we cannot return a pointer to a local variable.
Pointers are variables that live on the stack, but the memory they point to lives in the heap. - Command line arguments and environment variables. This segment is at the top of the program’s address space. The operating system stores this information for our program to use if needed.
Here is a diagram of the memory as described here:
Summary
- In this chapter we were introduced to pointers and references.
- Pointers can be used as references to other variables.
- Reference variables are aliases to normal variables.
- Pointers can be used to handle dynamically allocated memory